Master's Thesis
Data Pipelines in a PolyDBMS
The Master’s thesis is the final research project required to complete the degree. It is completed over the course of six months that follows an initial preparation phase of one month.
TL;DR
As part of my thesis, called Data Pipelines in a PolyDBMS, I created a novel data pipelining tool that is built on top of Polypheny. It enables the visual construction and execution of powerful multi-model data ingestion workflows. This makes it possible to work seamlessly with relational, document and graph data, all at the same time.
Limitations of Existing ETL Tools
To address complex data ingestion tasks, data engineers rely on ETL processes. They extract data from various heterogeneous sources into a staging area, transform (data cleaning, schema matching…) and load it into a single target system.
With the rise of data hungry AI systems and organizations wanting to gain more insights from increasingly diverse data, this approach has become insufficient. Existing ETL tools like Apache Airflow, Hop, NiFi or KNIME are inherently designed for processing tabular (relational) data. With the rise of NoSQL systems, data may no longer follow a fixed schema (e.g. a document database for product description) or is structured completely differently. For instance, relationships between users on a social media platform can be efficiently represented as a property graph.
A modern data ingestion tool must thus be able to work with the relational, document and graph model and facilitate mapping data between these models.
My Contributions
In my thesis, I extended the data pipeline concept that is used by ETL processes to support multiple data models. This is made possible by the innovative database system Polypheny.
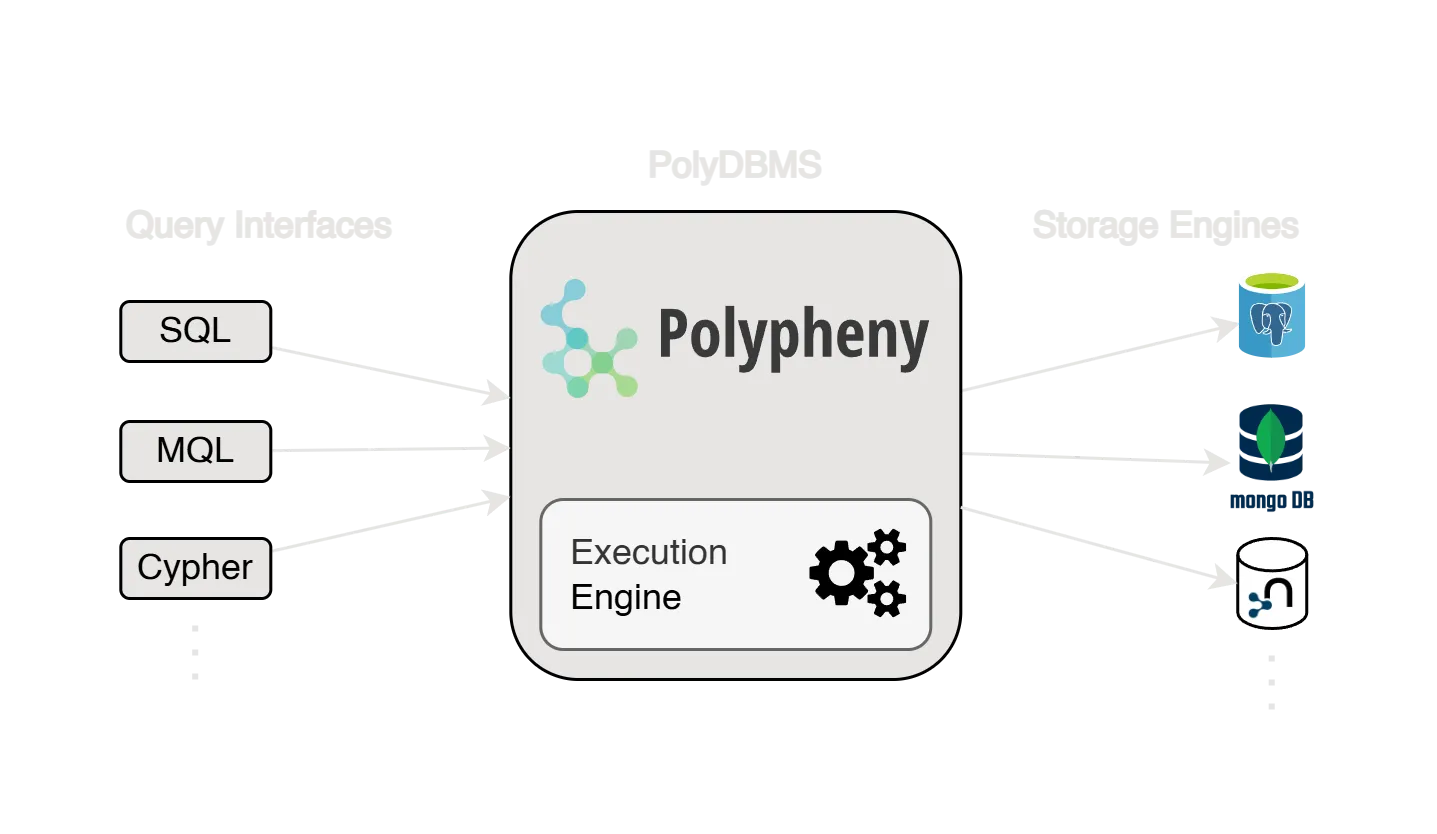
INFO
Polypheny is an instance of a PolyDBMS. It unifies access and management of heterogeneous data in different underlying storage engines. Any of its supported query languages can be used to query the data.

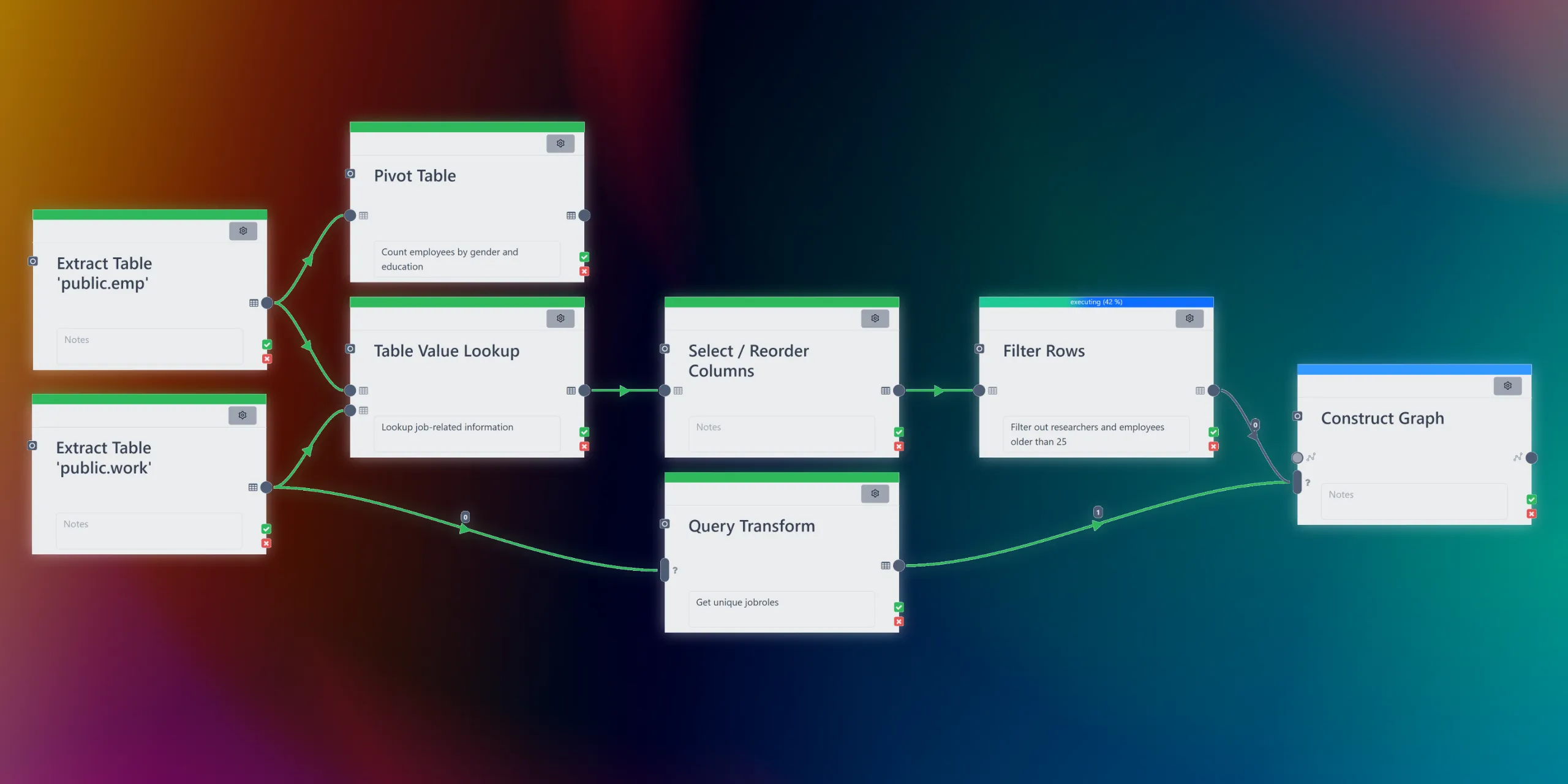
The project resulted in a workflow engine plugin for Polypheny and the addition of a visual workflow editor to its browser-based user interface. A workflow is a directed acyclic graph of connected processing steps that we call activities. Some of the things activities can achieve:
- Extracting data from CSV, JSON, XML or text files
- Schema Mapping
- Data cleaning
- Executing queries
- Mapping from one data model to another (e.g. constructing a graph from a table of users linked by a follower join table)
- Sending REST requests
- Executing custom transforms specified with Java code
- Loading data to Polypheny
Nested workflows, control edges and a variable system enable the orchestration of complex workflows. Execution of workflows can be automated and optimization techniques ensure good performance even for large ingestion tasks!
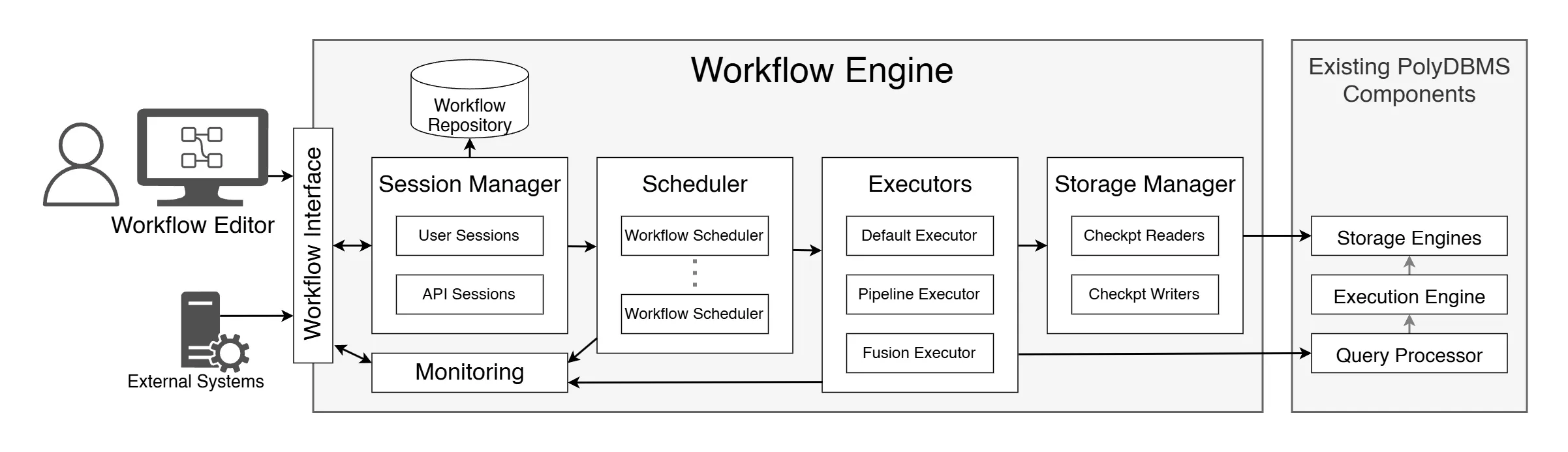
The workflow engine consists of different components, such as a scheduler that enables the concurrent execution of independent activities.
